Creating a News App for Android
This article offers a peek into how you can parse and render html content as native views on Android




During my early days of learning android development, one of the exciting projects I wanted to work on was a News App, specifically for gaming contents. Since I knew so little at the time, one of the roadblacks I faced was not having an idea on how html content could be rendered as native views on android as seen on popular news apps like IGN, or CNET. Online contents on building news app weren't all that helpful as well, because all articles I could find on this only explained how you could render a list of articles in a recyclerview, or showing them on a webview. None really covered the basis on parsing HTML and showing the full content of an HTML file.
Well after a really long while of tinkering with android development by working on other projects I could do, I became interested again with building a news app. I really wasn't sure of how I was going to do this, but I just kept going at it, trying out multiple ways of solving this problem. I downloaded a couple of news apps from the playstore to observe how these apps work, trying to see if any would "give in" on the secret of how they handled it lol, but all I could notice was that those content were rendered on a RecyclerView.
That was one piece of the puzzle that actually turned out to be really helpful. Knowing the contents were displayed on a recyclerview meant that the content of the news/article are being passed down as a list. Which gave rise to figuring out the solution to the next problem:
How to parse HTML content to a list
We know an HTML document comprises of text tags such as <p>, <a>, <i>, <em>, etc. It also contains container elements that holds group of elements as a single entity such as <div>, <section>, etc. Other popular elements are <img /> for images, <video /> for displaying videos, and lots more. We know what these elements are used for, and the task now is to figure out a way to transform these tags and their respective content to lists. As an example, I would be using the article template used by IGN. The sample article is at this link. After visiting the link, you'll need to right click on any part of the document and left click the "Inspect Element" option to display the HTML structure of the webpage.
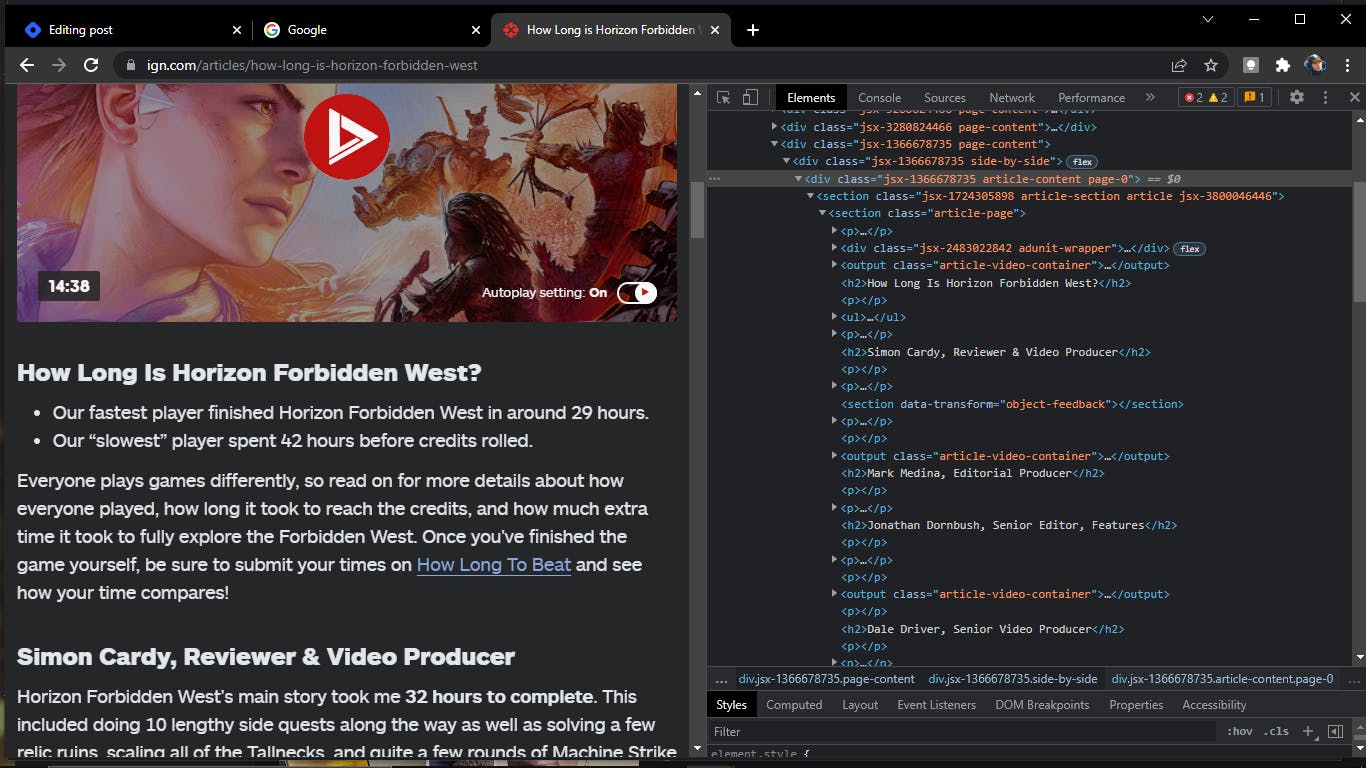
We need to understand the arrangement pattern generally used for articles. This way, we can imitate this pattern and figure out a way to grab the data we need, and pass them on to the list.
The solution? Traverse the HTML document
We'll need to pass through every element of the HTML content, and extract the data we need based on the kind it is (text, image, video, headers, etc). Luckily, there's a library that does this really well.
- Open up your Android studio, Create a project, and install the JSOUP dependency adding this one line of code in your app's
build.gradlefile.
implementation 'org.jsoup:jsoup:1.14.3'
Create an empty Kotlin file, and name it
ArticleParser.kt. This is the class that would be responsible for traversing the DOM and adding the content to an array list.Now we need to describe the data types that would be synonymous to the HTML tags. To do this, we'll create a new kotlin file that holds every possible type we'll be needing to represent our tags.
First is the HTML text tags like <p>, <i>, <a>. Since this tags are generally used to hold text, we'll have a global class name for this sort of text tags called Paragraph:
sealed class NewsArticle{
class Paragraph(val value:String): NewsArticle()
}
Before proceeding, we'll need to understand how the article section of the webpage is structured. Going back to "Inspect Elements", we'll observe that the body/content of the article is within a parent <section> tag, having one of its classnames as "article-content". This is would be the starting point of our traversal.
An important thing to note about JSoup types is that Node refers to any element or text content available on the HTML document. Element refers to only HTML element tags, not the text content. Element extends Node. And finallly we have TextNode which also extends Node, but refers to only the text content of an HTML file.
In our NewsArticle class, we'll be creating a function that accepts a Node variable, and we traverse the content of this Node.
suspend fun traverseElement(element: Node): List<NewsArticle>{
return withContent(Dispatchers.IO){
element.traverse(object: NodeVisitor){
override fun head(node: Node, depth: Int){
}
override fun tail(node: Node, depth: Int){
}
})
}
}
The head() method of the NodeVisitor interface is invoked when we encounter the start of an HTML element/text, and passes the corresponding node, and depth. The tail() method is invoked when we encounter the end of an HTML element, and this method also passes the corresponding node and depth during traversing the DOM. depth refers to the nested level of any of the nodes encountered during traversal. This means the start of any node encountered during traversal has a depth of 0. If this node contains sibling nodes, the sibling nodes would have a depth of 1, 2, 3, ...n.
It'll be ideal to handle text nodes, before any other forms of nodes. Mostly beccause, we need to figure out a way to concatenate texts as a single entity, regardless of any form they might come in such as Regular texts, Bold texts, Italic, or Link texts. Here's a sample of what I mean:

If you observe the text above, you'll notice it comprises of regular, bold, and italics. We wouldn't want these various element break down into different blocks while traversing through all the elements and adding them to a list. So to achieve this, we'll create a nullable NewsArticle object that holds the current node during traversal, and we'll check to see if it is a type of NewsArticle.Paragraph. If it is, we concatenate the next text with the previous text. If it isn't, we'll add the exisiting NewsArticle object into the list, and create a new NewsArticle.Paragraph object.
var articlePiece: NewsArticle? = null
private fun resolveArticleParagraph(word: String): NewsArticle {
val temp = word.replace("\\\\s+", "")
return if (temp.isNotEmpty()) {
return if (articlePiece != null && articlePiece is NewsArticle.Paragraph) {
NewsArticle.Paragraph((articlePiece as NewsArticle.Paragraph).value.plus(word))
} else {
NewsArticle.Paragraph(word)
}
} else {
NewsArticle.Paragraph("")
}
}
suspend function traverseElement(element: Node): List<NewsArticle>{
return withContent(Dispatchers.IO){
element.traverse(object: NodeVisitor{
override fun head(node: Node, depth: Int){
if (node is TextNode) {
val word = node.text()
articlePiece = resolveArticleParagraph(word)
}
}
override fun tail(node: Node, depth: Int){
}
})
}
}
This piece of code above only transforms all of the text as regular text. Now we'll need to do something that would show a distincition between regular texts, link texts, and any other form of text.
We'll write an extension function for the Element node, to determine if the type of tag encountered during traversal is a text element.
open class RegularText(val text:String)
class ItalicText(text: String):RegularText(text)
class LinkText(text: String):RegularText(text)
class BoldText(text: String):RegularText(text)
fun Element.isText(): Boolean {
val tag = this.tagName()
return tag == "a" || tag == "em" || tag == "i" || tag == "p" || tag == "strong"
}
fun Element.getTextType(): RegularText {
val tag = this.tagName()
val text = this.text()
return when (tag) {
"a" -> LinkText(text)
"i", "em" -> ItalicText(text)
"strong" -> BoldText(text)
else -> RegularText(text)
}
}
Now back to our traverseElement() method, we'll modify the code to be aware of various forms of text tags we need to look out for:
private fun openArticleLink(): NewsArticle {
return if (articlePiece != null) {
if (articlePiece is NewsArticle.Paragraph) {
NewsArticle.Paragraph((articlePiece as NewsArticle.Paragraph).value.plus("["))
} else {
//when a paragraph starts with a link sentence
addToArticle()
NewsArticle.Paragraph("[")
}
} else {
NewsArticle.Paragraph("[")
}
}
private fun openArticleItalic(): NewsArticle {
return if (articlePiece != null) {
if (articlePiece is NewsArticle.Paragraph) {
NewsArticle.Paragraph((articlePiece as NewsArticle.Paragraph).value.plus("_"))
} else {
//when a paragraph starts with an italic sentence
addToArticle()
NewsArticle.Paragraph("_")
}
} else {
NewsArticle.Paragraph("_")
}
}
private fun openArticleBold(): NewsArticle {
return if (articlePiece != null) {
if (articlePiece is NewsArticle.Paragraph) {
NewsArticle.Paragraph((articlePiece as NewsArticle.Paragraph).value.plus("*"))
} else {
//when a paragraph starts with an italic sentence
addToArticle()
NewsArticle.Paragraph("*")
}
} else {
NewsArticle.Paragraph("*")
}
}
private fun closeArticleLink(link: String): NewsArticle {
return if (articlePiece != null && articlePiece is NewsArticle.Paragraph) {
NewsArticle.Paragraph((articlePiece as NewsArticle.Paragraph).value.plus("]".plus("(${link})")))
} else {
NewsArticle.Paragraph("")
}
}
private fun closeArticleItalic(): NewsArticle {
return if (articlePiece != null && articlePiece is NewsArticle.Paragraph) {
NewsArticle.Paragraph((articlePiece as NewsArticle.Paragraph).value.plus("_"))
} else {
NewsArticle.Paragraph("")
}
}
private fun closeArticleBold(): NewsArticle {
return if (articlePiece != null && articlePiece is NewsArticle.Paragraph) {
NewsArticle.Paragraph((articlePiece as NewsArticle.Paragraph).value.plus("*"))
} else {
NewsArticle.Paragraph("")
}
}
suspend function traverseElement(element: Node): List<NewsArticle>{
return withContent(Dispatchers.IO){
element.traverse(object: NodeVisitor{
override fun head(node: Node, depth: Int){
if (node is TextNode) {
val word = node.text()
articlePiece = resolveArticleParagraph(word)
} else if (node is Element) {
if (node.isText()) {
if (node.getTextType() is LinkText) {
articlePiece = openArticleLink()
} else if (node.getTextType() is ItalicText) {
articlePiece = openArticleItalic()
} else if (node.getTextType() is BoldText) {
articlePiece = openArticleBold()
}
}
}
override fun tail(node: Node, depth: Int){
if (node.isText()) {
if (node.getTextType() is LinkText) {
val link = node.attr("href")
articlePiece = closeArticleLink(link)
} else if (node.getTextType() is ItalicText) {
articlePiece = closeArticleItalic()
} else if (node.getTextType() is BoldText) {
articlePiece = closeArticleBold()
}
}
}
})
}
}
Here's an explanation of what is happening above:
When we encounter a LinkText, instead of passing off the whole text to the list as a raw text, we'll do a bit of markdown syntax such that the text ends up being like [some text here](https://link.com) or _text should be in italics_
Now how do we know when we are done with a block so it can be added as an item to the list. The idea was to delegete breaks at the tail(), such that when we get to the closing tag of an element at a particlar depth level, the current NewsArticle object is added to the list and reinitialized to null again for the next traversal.
The tail() method ends up being with the following snippet:
if (depth == articleParserConfig.breakDepth) {
addToArticle()
addSpacer()
}
Handling the text nodes is where the majority of the work is. Finally, you'll be needing Regex and android's SpannableStringBuilder to properly format and style the text based on the kinds they are. With this idea, considerations for other Container Elements such as images, videos, gallery views can easily be implemented. The full source code for the sample project can be found here